
今回は、KHCoderにおける対応分析の手順やメリットについてご紹介していきます。
対応分析は、語と語の関係性を散布図で視覚化できる分析方法です。
別名、「コレスポンデンス分析」とも呼ばれます。
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
対応分析のメリット

対応分析のメリットといえば、
抽出語同士や、抽出語と外部変数の関係性を散布図として視覚的に把握できる点です。
特に、分析したい語や変数が多い場合に便利な分析です。
対応分析のための分析ファイルは、外部変数の入力が容易なExcelもしくはcsv形式がおすすめです。
(テキストファイルでも可能ですが、外部変数の入力が複雑です。)
今回はExcel形式で収集した、Mr.Childrenの歌詞(テキストファイル)とリリース年(外部変数)のデータを例に、対応分析をみていきましょう。
対応分析の手順

まず、「ツール」→「抽出語」→「対応分析」をクリックしていきます。
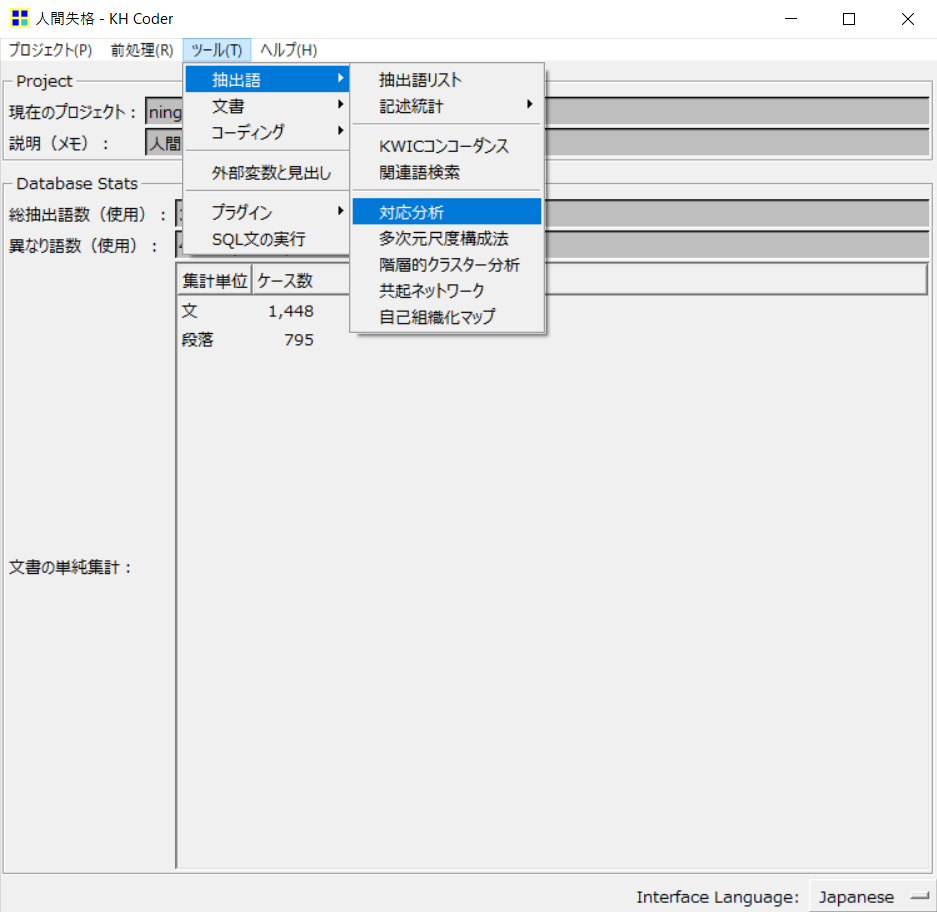
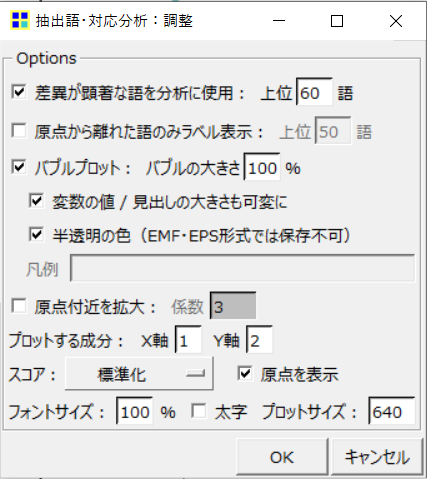
そうすると、以下のような設定画面が出てきます。
ちなみに、ここでの設定画面の左側の部分(抽出語の選択)も、KHCoder共通のものとなっています。
対応分析の醍醐味である外部変数との関連を見るためには、「抽出語×外部変数」を選択し、分析に使う外部変数(今回は、リリース年)を選択します。
まずは、それ以外はデフォルトで「OK」をクリックしてみます。
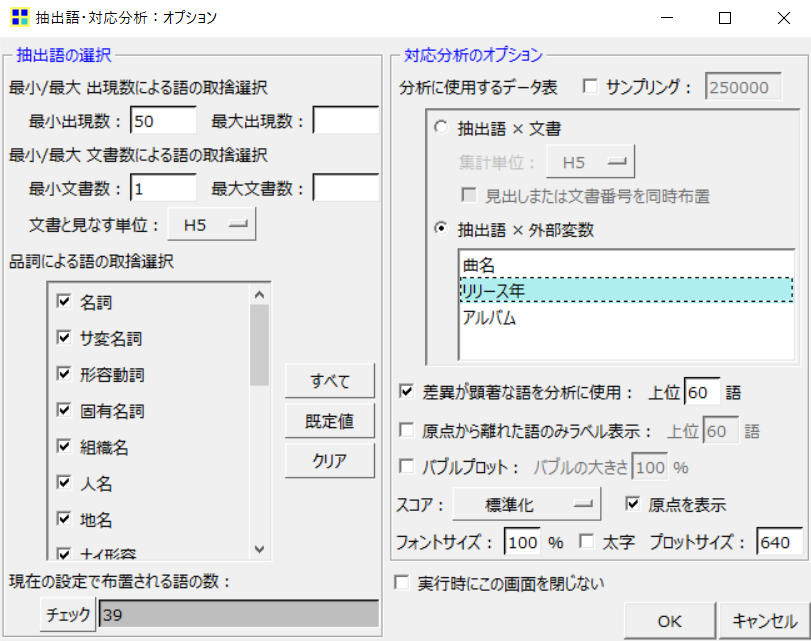
すると、以下のような分析結果が出てきました。
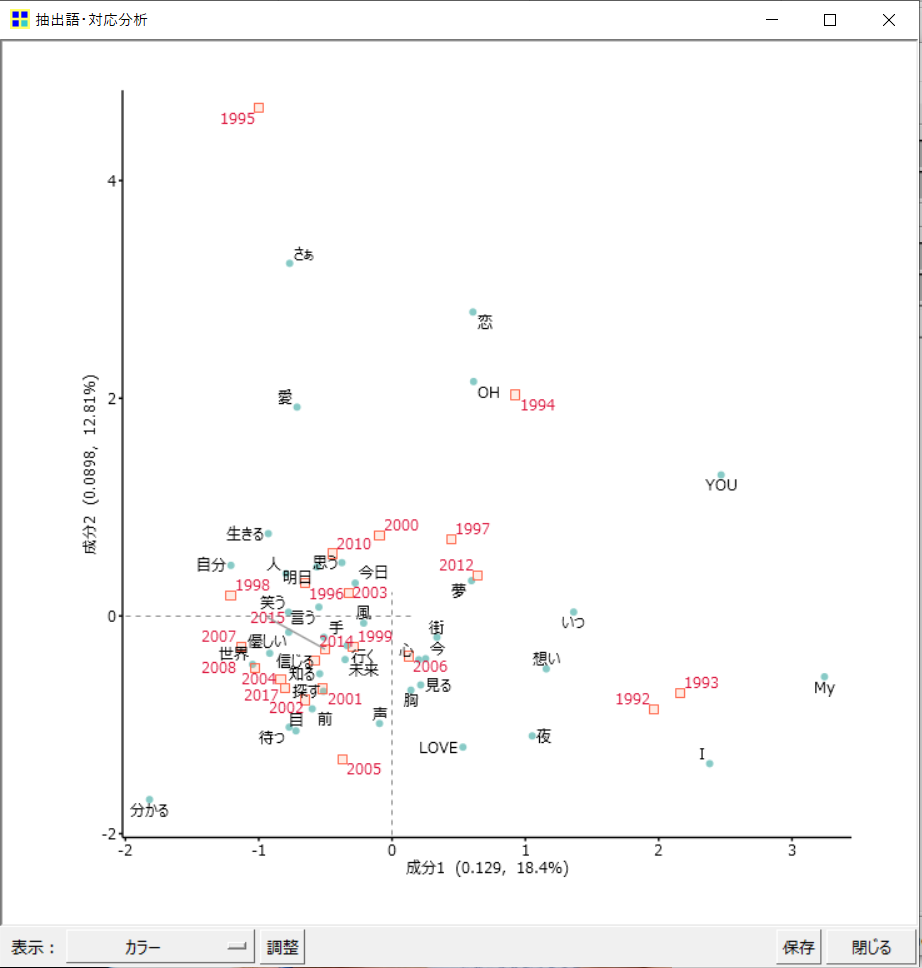
散布図なので、リリース年と抽出語の関係が直感的に分かりやすいですね。
しかし、原点(縦軸と横軸の0が交わる点)付近に語が密集しており、少し読み取りづらい箇所もあります。
そんなときは、分析結果画面下の「調整」から設定画面を出し、「原点付近を拡大」をクリックします。
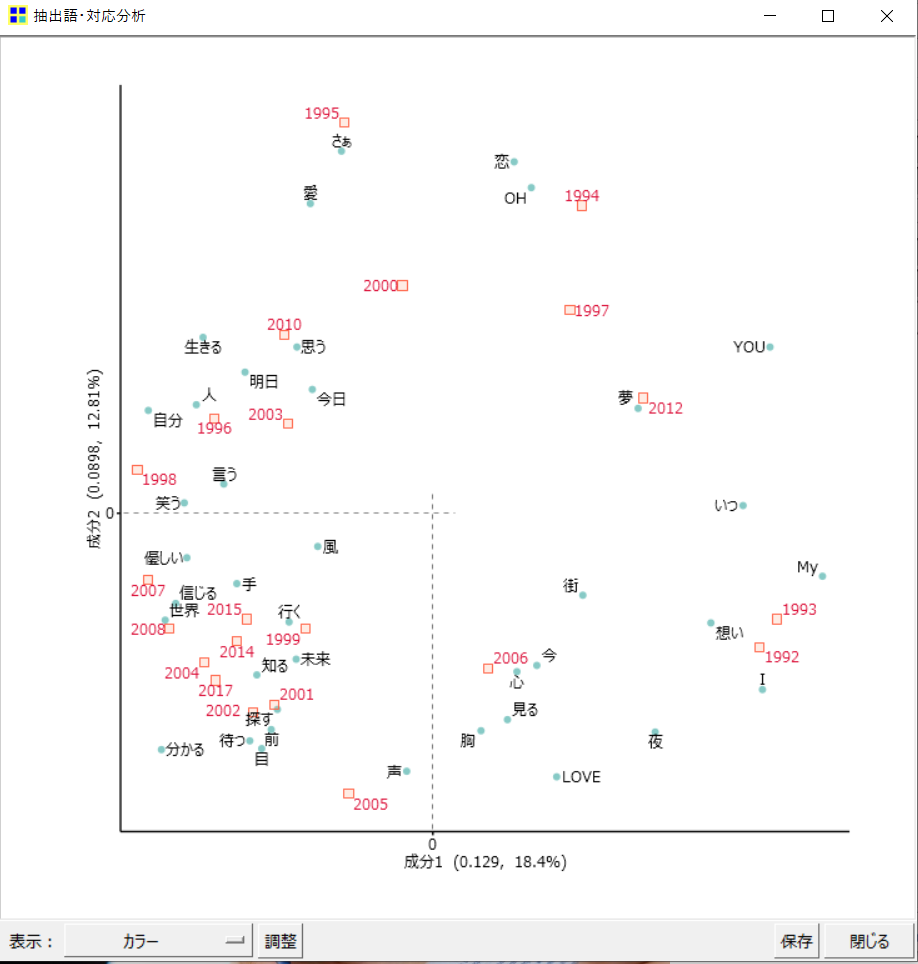
そうすると、設定通り原点付近が拡大され、分析結果が読み取りやすくなりました。
ただし、これはあくまで分析結果を見やすくしたものなので、本来の純粋な分析結果とは少し異なります。
それを理解したうえで、使用しましょう。
次に、この図をどう読み取ればよいのかをご説明します。
分析結果の読み取り方

対応分析の図を読み取るうえで重要なポイントは、以下の2点です。
ポイント
- 原点(縦軸と横軸の0が交わる点)から離れているほど、特徴的な語である。
- 関連の強い語と外部変数は近くに位置する
また、外部変数同士が近くに位置している場合、抽出語や、その出現回数が似ているということを示しています。
今回の対応分析の結果でいえば、
Mr.Children初期の1992年、1993年は互いに使用している語が似ており、ほかの年代と比べると、特徴的な語(I、My、想いなど)が使われているということが分かります。
そのほかにも上記の図から多くの特徴が読み取れますので、是非考えてみてください!
(例)
- 1997年と2012年の歌詞は似ている。
- 「夢」という語は、2012年の歌詞に特徴的な語である。
- 全体的に見て、ネガティブな語が少ない。
また、抽出語の条件を変えてみたりすると分析結果も変わるので、いろいろ試してみることも大切です!
バブルプロットを使いこなそう!

KHCoderでは、対応分析の結果をバブルプロットで表すこともできます。
バブルプロットとは、データの点を円(バブル)で表現した散布図のことです。
通常の散布図からは読み取れないデータそのものの大きさ(語の出現回数を表したもの)も確認することが出来ます。
分析結果画面下の「調整」をクリックすると設定画面が出てくるので、バブルプロットにチェックをつけます。
今回は、「原点付近を拡大」にもあらかじめチェックしておきましょう。
すると、以下のような分析結果が出てきます。
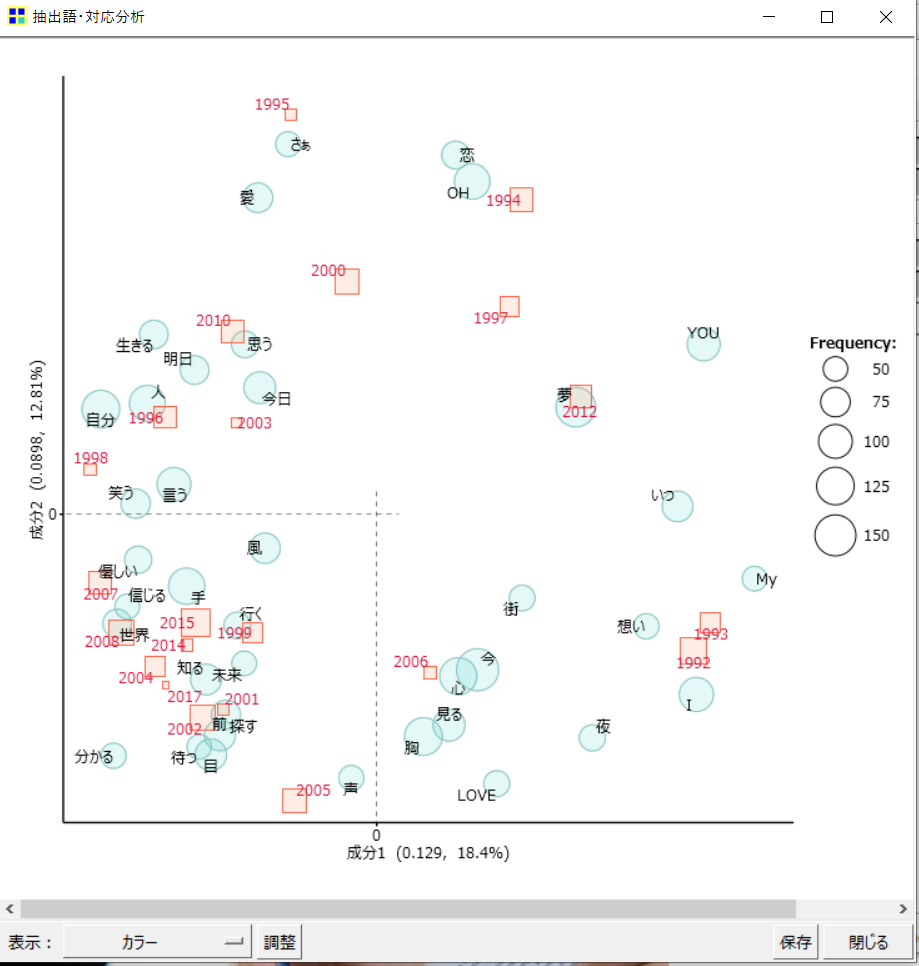
先ほどの画面に加え、語に赤い円が、外部変数に青い四角がプラスされました。
これで、それぞれの語について、だいたいどれくらいの回数かが分かるようになりました。
また、共起ネットワークやクラスター分析と同様、分析結果の語をクリックすると、KWICコンコーダンスを確認することができます。
様々な分析を組み合わせて、自分なりの分析・考察をしていきましょう!
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
↓この記事を読んだ方の多くは、以下の記事も読んでいます。




