
前回の記事では、KHCoderのインストールをしました。
インストールが完了したら、次は分析用テキストファイルを準備していきましょう。
分析用テキストファイルを作り方は、分析の種類によって少し異なります。
分析用テキストファイルを作り方
- 「テキストデータ」の分析
- 「テキストデータ」×「文章に対応する変数」の分析
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
分析データの準備
「テキストデータ」の分析

まずは、シンプルなテキストデータのみが対象の分析です。
これは文章の要点やテーマなど、文章の全体像をつかみたい場合に適している基本的な分析で、他の変数を絡めた分析は行いません。
ちなみに、一つのテキストファイルだけでなく、複数のテキストファイルを同時に分析することも可能です。
複数のテキストファイルを分析する際は、1つのフォルダにテキストファイルをまとめてから、「プロジェクト」→「インポート」→「フォルダ内の複数テキスト」で「結合ファイル」を作成することができます。
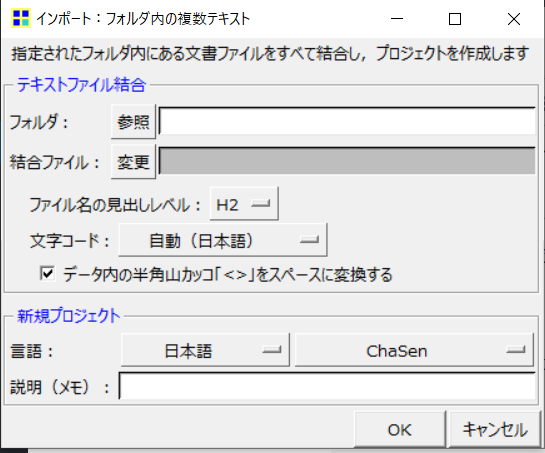
そのほかの準備方法として、
Excelファイル内に、テキストデータを入力して、分析ファイルを作成する方法もあります。

多くのテキストファイルを作成して管理するのが面倒なので、私はこのやり方がメインです。
(Excel形式で分析ファイルを作っても、新規プロジェクト作成時にExcelをもとにしたテキストファイルが自動で作成されるため、分析には問題ありません。)
このあたりは人それぞれなので、自分に適した方法でやっていきましょう!
「テキストデータ」×「文章に対応する変数」の分析

KHCoderでは、テキストデータだけでなく、
テキストデータに変数を組み合わせて分析することも可能です。
たとえば、
「アンケートの自由記述回答文と回答者の属性(性別や年代など)を組み合わせて分析することで、属性ごとの回答の特徴を探る」
といったことが可能です。
「テキストデータ」と「変数」を組み合わせた分析をする場合は、
Excelに文章と外部変数を入力して、分析ファイルを作成します。
私は趣味で、ミュージシャンの歌詞を分析しているのですが、
その際、以下のような形式で分析用ファイルを準備しています。
(変数は分析によって追加することもあります。)

A列はタイトル、B、C列が変数、D列がテキストデータ(歌詞)です。
まずは、自分が「どんな分析をしたいのか」を考えてみましょう。
そのあとで、その分析に適した形式のファイルを作っていきます。
データクレンジングの重要性

それでは実際に、テキストデータを準備していきましょう。
本記事では、青空文庫からテキスト形式でダウンロードしてきた、
太宰治の『人間失格』をサンプルデータとして使っていきます。
※青空文庫(https://www.aozora.gr.jp/)・・著作権が消滅した作品や著者が許諾した作品のテキストを公開しているインターネット上の電子図書館。(wikipediaより)
テキストデータを使う際の注意点は、
分析に不要な文字が含まれていないかを確認することです。
これがめちゃくちゃ重要です。
どういうことか。
百聞は一見にしかず、ということで、
実際に青空文庫からダウンロードしたテキストファイルをご覧いただきましょう。
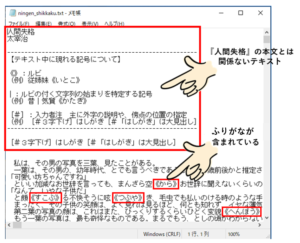
あくまで『人間失格』の本文を分析したいにも関わらず、
本文に関係のない文章や、ルビ(ふりがな)などの余分な文字が多数含まれてしまっています。
そこで分析に移る前に、
まずはテキストが本当に分析に適した形になっているのかどうかを確認します。
なっていなければ、分析に適した形に修正しなければなりません。

このデータを分析に適したキレイな形にする作業のことをデータクレンジングと呼びます。
※データクレンジングは、テキストマイニングでよく出てくる言葉なので、覚えておくと便利です。
私は普段、秀丸というテキストエディタ(有料)を使って、データクレンジングを行っています。(https://hide.maruo.co.jp/software/hidemaru.html)
今回は、具体的なデータクレンジングの方法については割愛しますが、
秀丸を使ってデータクレンジングをしたことで、下の図のように分析しやすいキレイなテキストデータになりました。

文字が多く、少し窮屈そうに見えますが、分析を邪魔する余分なものがなくなったので、非常にテキストマイニングがしやすい形になりました!
そして、より具体的にデータクレンジングの重要性を示すために、
データクレンジング前と後のデータで、それぞれ形態素解析してみました。
その結果が以下の図です。
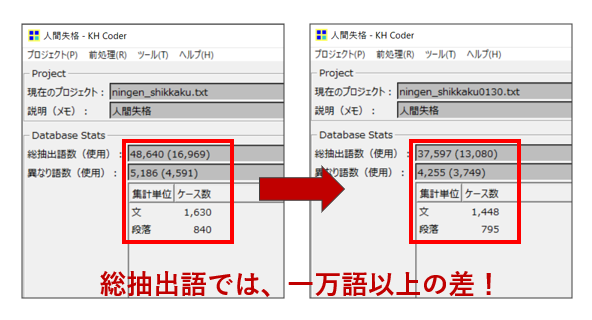
すると、なんとデータクレンジングをする前と後で、総抽出語数1万語以上の差がありました!
つまり、データクレンジングをしていなかった場合、
1万語以上の余分な言葉を含んだデータの分析をするということになります。
そんなデータを使った分析は、非常に信頼性に欠けますよね。
どれだけ優れた分析を行っても、そもそもの分析対象が誤っている場合、誤った分析結果しか出ません。
でも、いきなり最初から秀丸などのソフトを使ったデータクレンジングはハードルが高いかもしれません。
ですので、最初のうちは手動で修正できる量の分析から始めるのが良いと思います。
数は多くなくても、質の高いデータを集めて分析することが、正しい分析結果を導き出す近道だからです。
テキストマイニングでは、データ量よりもデータの質が大切です。
有料版のテキストエディタを使うのは、実際にテキストマイニングをしていく中で、
「もっとたくさんのデータを使って、本格的にテキストマイニングをしたい!」と思うようになってからの方がよいでしょう。
KHCoderでの分析の準備
新規プロジェクト作成

さあ、分析ファイルの準備が完了したら、KHCoderに取り込んでいきましょう。
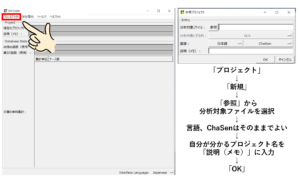
まずは、「プロジェクト」→「新規」をクリック。
参照をクリックして、「分析対象のファイル」を選択します。
説明(メモ)欄に、今後プロジェクトを開くときに、自分が分かるようにメモを入力します。
(本記事では、そのまま「人間失格」と入力します。)
入力が完了したら、OKをクリック。
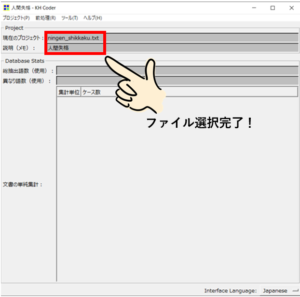
これで、分析対象ファイルを選ぶことが出来ました。
ちなみに、ここでいう「言語」は、分析対象ファイルの言語のことです。
青空文庫からダウンロードした『人間失格』は日本語なので、言語はデフォルトの日本語でOKです。
また、その右に出てくる「Chasen」というのは形態素解析エンジンと呼ばれるものです。(日本語ではChasenかMeCabが選べます。)
この形態素解析エンジンに組み込まれている単語リストを使って、文章を形態素に分割したり、品詞を判別したりします。
ChasenとMeCabの違いは簡単にいうと、以下のようなイメージです。
- Chasen・・・KHCoder上での、複合語の検出で動作環境が良い。
- MeCab・・・RやPythonでMeCabを用いたテキストマイニングの環境があれば、KHCoderでも互換性がとれる
今回は、RやPythonは使用していないため、デフォルトのChasenのままで問題ありません。
分析対象ファイルのチェック

次に、分析対象ファイルのチェックです。
「前処理」→「テキストのチェック(分析対象ファイルのチェック)」を選択します。
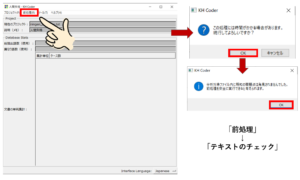
ここでは、分析できない文字が含まれていないか、ファイルが分析可能な形式のものか、などのチェックをしています。
分析できない文字がある場合は、以下のようなエラーが出てきます。
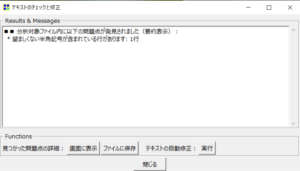
「画面の表示」をクリックすれば、どこがエラーなのかわかるので、修正しましょう。
どうやら今回は、文章の中に顔文字が含まれていたので、エラーになったようです。
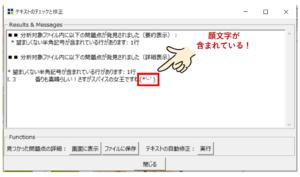
また、テキストの自動修正をクリック、エラー箇所を自動修正することも可能です。
前処理の実行
最後に、「前処理」→「前処理の実行」をクリックします。
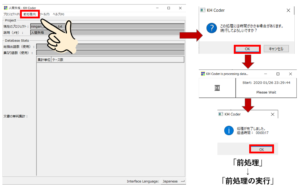
前処理の実行では、形態素解析が行われています。
テキストマイニングでは、文章をそのまま分析するのではなく、
まず形態素解析という準備段階を経て、ようやく分析のスタートラインに立つことが出来るです。
前処理が完了すると、以下のような画面になります。
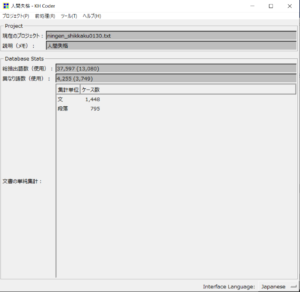
これで、前処理の実行が完了しました!
前処理(形態素解析)の結果、青空文庫からダウンロードした『人間失格』の総抽出語数は37,597語と言うことが分かりました。
※ちなみに、総抽出語数のあとにある(使用)は、分析に使用する語数を表しています。助詞などの「分析に使用しない品詞」をKHCoderが自動で省いてくれます。
分析を始めよう!

少し長くなってしまいましたが、これで分析の準備は万端です!
最初こそ大変かもしれませんが、慣れれば早くできるようになります。
また、どんな結果になるんだろうと想像すると、
データ収集やデータの準備も楽しみながらできるようになります。
さて、前処理まで終えると、
いよいよ対応分析、クラスタ分析、共起ネットワークの作成などの様々な分析が可能になります。
次回からは、具体的な分析方法の紹介をしていきます。
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
↓この記事を読んだ方の多くは、以下の記事も読んでいます。




