
今回の記事のテーマは共起ネットワークです。
これが使いたくてKHCoderを始める人もいるというくらい人気のある分析手法です。
さて、共起ネットワークに入る前に少しだけ前回の記事のおさらいです。
抽出語リストから、『人間失格』のなかで最も多く現れる語は「自分」だということが分かりました。
そして、その「自分」に関するコロケーション統計を行った結果、
「ない」「ぬ」「ん」などの否定助動詞とともに使用されていることが多いと言うことが分かりました。
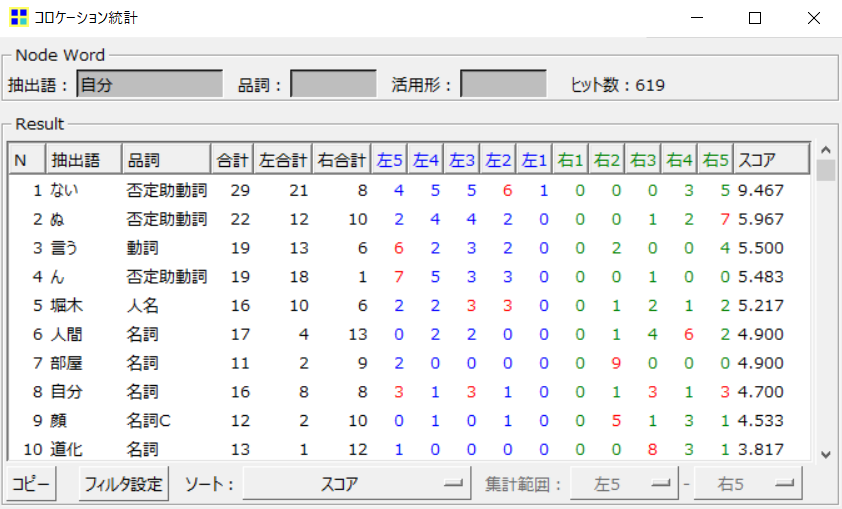
しかし、このようなコロケーション統計の表では、直感でイメージがつかみにくいかもしれません。
みなさんは、会社や学校などで、Excelにまとめた数字の特徴を一目で分かるようにするためにはどうしていますか?
そうです、グラフ化です!
グラフという図を使うことで、より多くの人々が直感的に特徴を把握できるような工夫をしますよね。
テキストマイニングにおいてもグラフ化のように視覚的に特徴が捉えやすい、図を使った表現方法があるのです!
今回ご紹介するのは、KHCoderのなかで直感的わかりやすさNo.1の共起ネットワークです。
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
共起ネットワークとは

共起とは、 「複数の言語現象が同一の発話・文・文脈などの言語的環境において生起すること(三省堂 大辞林 第三版より) 」という意味です。
そして共起ネットワークは、文章中に出現する語と語がともに出現する関係性を図にしたものです。
共起ネットワークを使うことで、直感的に文章の特徴を捉えやすくなるというメリットがあります。
共起ネットワークの作成方法

それでは共起ネットワークを実際に作成してみましょう。
まずは、「ツール」→「抽出語」→「共起ネットワーク」とクリックしていきます。
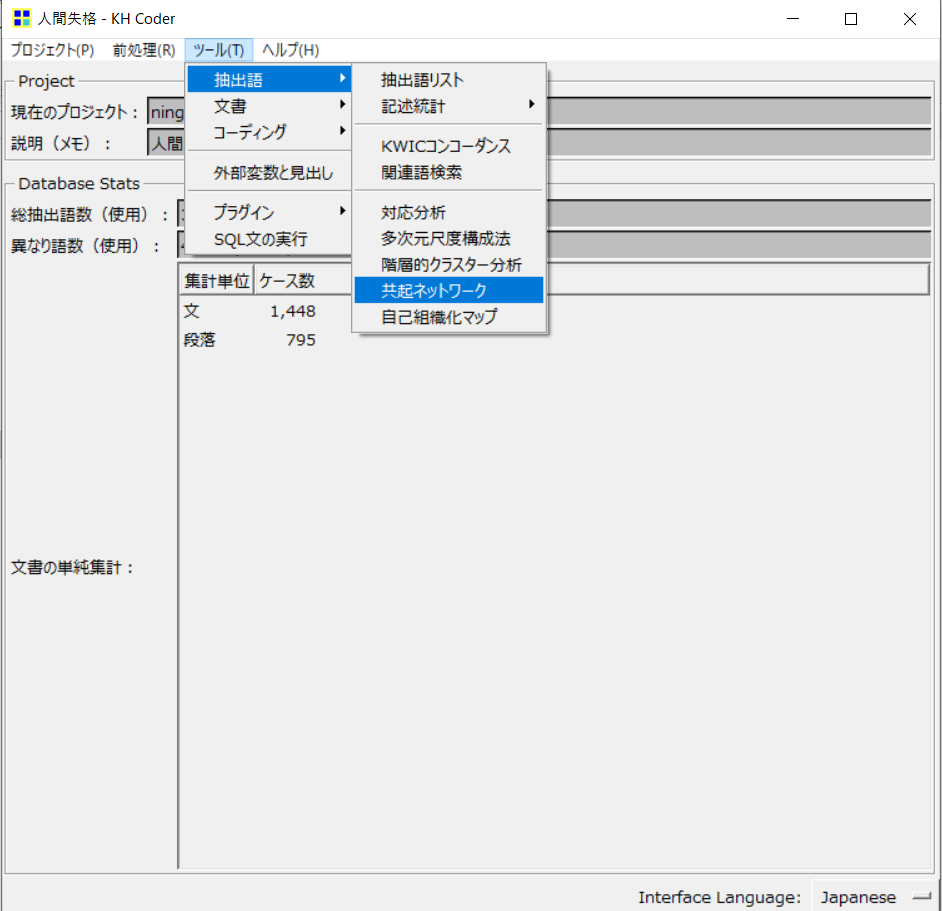
そうすると、以下のような共起ネットワークの設定画面が出てきます。
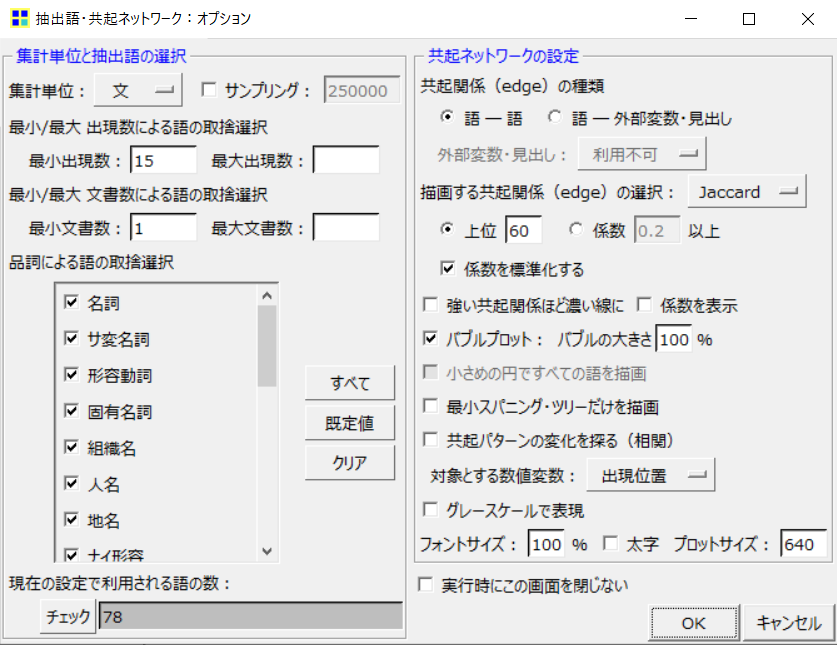
この画面で、どのような共起ネットワークを作成するか、細かく決めることが出来ます。
いろんな項目がありすぎて、最初は何を設定したらいいか分かりにくいかもしれませんので、まずはデフォルトの状態で「OK」をクリックしてみましょう。
※設定は後から何度でも変えられますので、出てきた共起ネットワークをもとに、設定を修正していけば大丈夫です。

「OK」をクリックすると、上のような共起ネットワークが作成されました。
いくつかのグループに分かれて表示されたり、それぞれ関連の強い語が結びついていたり、あたらしい発見はあるものの、
デフォルトのままでは少し見にくく、直感的に分かるとはいえないかもしれません・・・
あとで調整していきましょう。
共起ネットワークの見方
調整の前に共起ネットワークの読み取り方をお伝えします。
読み取り方はいたってシンプルです。
以下の2つのルールさえ覚えればOKです。
- 出現回数が多い語ほど円が大きい。
- 線と線で結ばれている語は関連性が強い。
先ほどの共起ネットワークで、「自分」というキーワードだけ突出して大きかったのは、そのためです。
(抽出語リストより、出現回数1位の語は「自分」で619回、2位の語は「言う」で127回と、ダントツで「自分」が多いことが分かっています。)
ちなみに、円の位置や近さには全く意味がないので、注意してください。
また、サブグラフ検出というのは、 互いに強く共起している語を自動的に検出してグループ分けを行うことです。
今回の場合では、11個のグループに分かれました。
グループ分けのような意味合いでは、次回以降の記事でご紹介する階層的クラスター分析の方が有効ですので、こちらは共起ネットワークのオマケのようなイメージでよいかと思います。
共起ネットワークの詳しい設定
さて、これからは、より自分の分析に適した共起ネットワークを作成できるよう、よく使う詳細な設定方法をご紹介します。
デフォルトの少し読み取りにくかった共起ネットワークを改善していきます。
最小/最大出現数による語の取捨選択
最小出現数を指定すると、指定した回数以上出現した語しか現れません。
これによって、たいして出現回数が多くない語が、共起ネットワークに出てきてしまうのを防ぐことができます。
例として、今回の共起ネットワークで最小出現数を15回から30回に変更して、左下のチェックを押します。
そうすると、対象となる語数が「78語」から「26語」になり、かなり厳選されました。
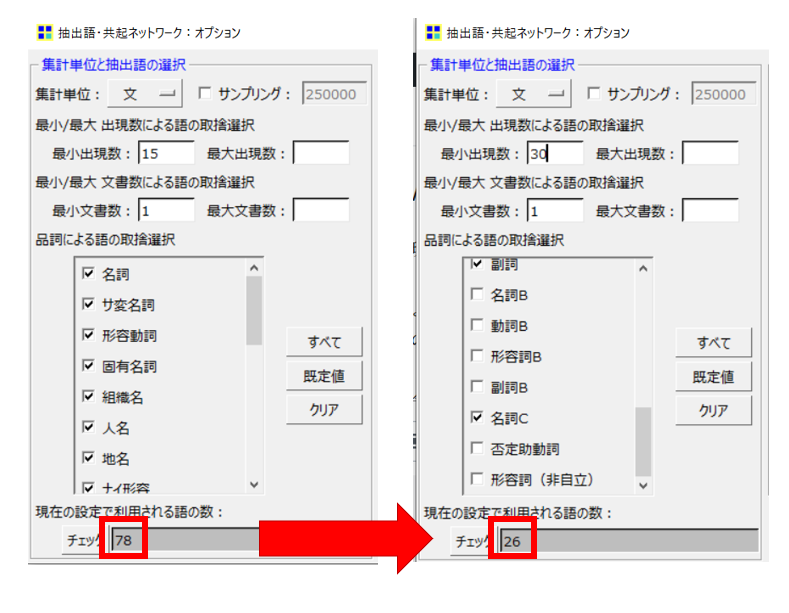
これを実際に図にすると、その差は一目瞭然です。

ただ、注意してほしいのは、決して表示される語数が少なければいいという訳ではないということです。
少なすぎても特徴は掴めませんし、多すぎても掴みにくいです。
色々試して、ちょうどいい塩梅を見つけてください。
補足ですが、よく見ると「語の取捨選択」の種類が「出現数」と「文書中」の2種類あります。
これらは
- 「出現数」・・・データ全体のなかでの出現数
- 「文書中」・・・いくつの文章に現れたか
ということを示しています。
特にこだわりがなければ「出現数」(データ全体)で分析するのが無難だと思います。
品詞による語の取捨選択
抽出後リスト同様、こちらも品詞で共起ネットワークを構成する語を絞ることができます。
今回の場合、「ない」「ぬ」「ん」という否定助動詞が出現回数上位に上がっていますが、デフォルトでは否定助動詞は含まれていません。
先ほどまで掲載した共起ネットワークにも否定助動詞は現れていません。
出現回数上位の語が除外されて集計されると、本来出てくるべき結果とは異なる結果が出てきやすくなります。
なので今回は、否定助動詞を入れて、あまり関係なさそうな感動詞・未知語・タグを外してみます。
すると、以下のような共起ネットワークができました。
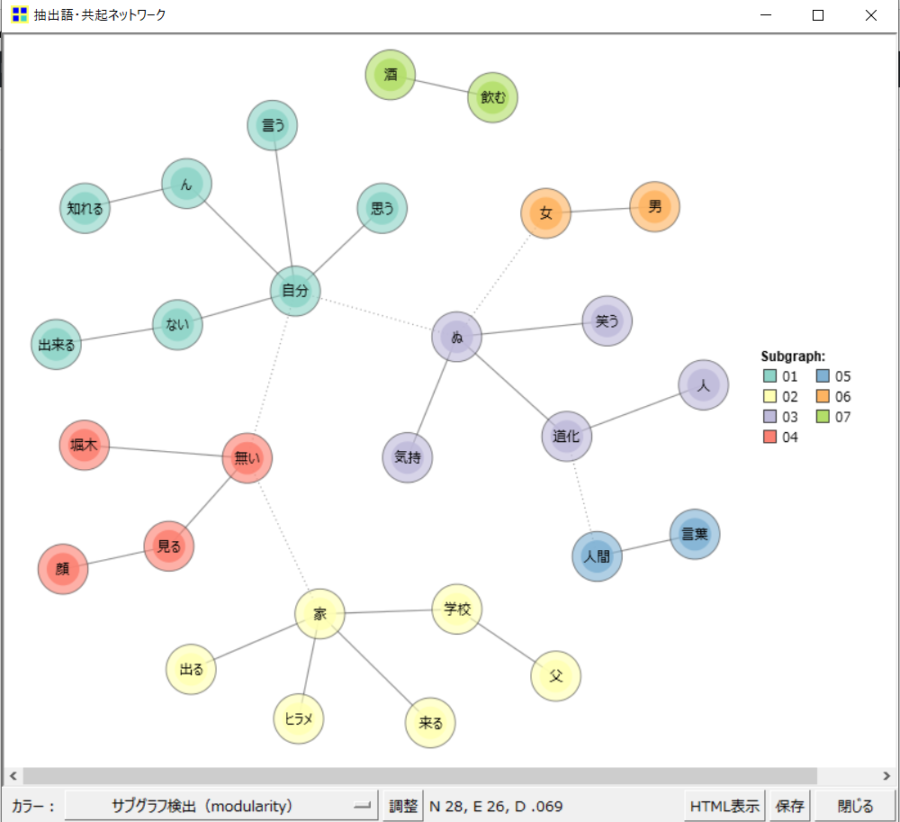
「自分」と共起性の強い否定助動詞たちが、ちゃんと出てきましたね。
そしてこの図では、その否定助動詞と共起性が強い他のキーワードも一目で分かるようになりました。
抽出語では上位だった語が出てきてない!と思ったら意外と品詞で除外されてることもよくあります。
分析に必要な品詞を見極めることが大切です。
共起性の種類
テキストデータのみの分析の場合は、「語-語」しか選択できません。
テキストと変数を組み合わせた分析では、「語-外部変数」の凶器ネットワークが作成できます。
たとえば以下の図のように、Mr.Childrenの曲の歌詞と、リリース年で共起ネットワークを作成することもできます。
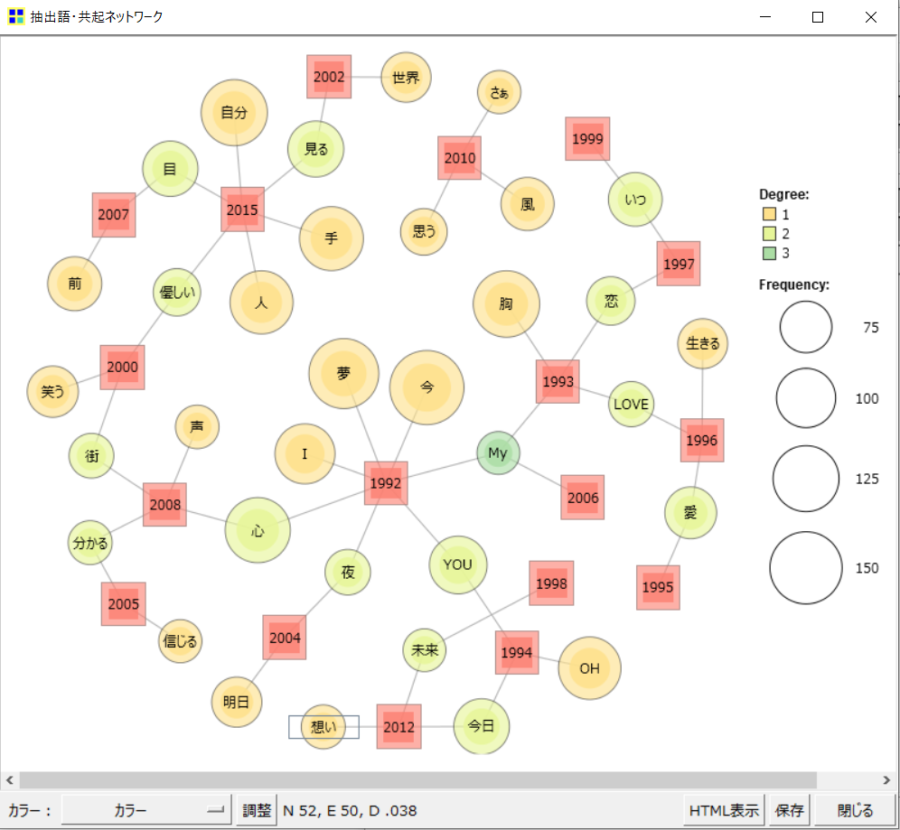
描画する共起関係(edge)の選択
こちらも共起ネットワーク内の語数が多くなってしまったときに調整するためによく使ったりします。
また、共起性が強い語だけをピックアップして共起ネットワークを作りたいときは、Jaccard係数を設定することも有効です。
Jaccard係数とは、語と語の関連性、共起性の程度を示す指標です。
計算方法は、
「語Aと語Bが同時に出現した数÷語Aもしくは語Bのいずれかだけでも出現した数」ですが、これは特に覚えなくてよいです。
それよりも、参考の指標を知っておくことのほうが有益です。
Jaccard係数の目安としては、
- 0.1→関連あり
- 0.2→強い関連あり
- 0.3以上→とても強い関連あり
というふうに考えられることが多いです。
ただし、テキストデータによっては、0.1以下でもとても関連が強いとされる場合もあるので、あくまで一つの参考にとどめておくのが良いと思われます。
強い共起関係ほど濃い線に
そのままの意味ですが、関連が強い語と語を結ぶ線ほど濃くなり、視覚的に共起性を読みとることができるようになります。
係数を表示
こちらに☑をつけると、語と語を結ぶ線のうえに、Jaccard係数が表示されます。
ついでに、さきほどの「強い共起関係ほど濃い線に」にもチェックをつけて共起ネットワークを作成すると、以下のようになりました。

共起性ネットワークを一目みたときに、関連の強さを表す数字も同時に確認できるので、便利な機能です。
ただし、共起性を表す線が多いときにこれを使うと、さらにごちゃごちゃになってしまうので、注意が必要です。
最小スパニングツリーのみを描画
めちゃくちゃおおざっぱにいうと、共起性の強い線だけの描画に絞って、図をシンプルにする機能です。
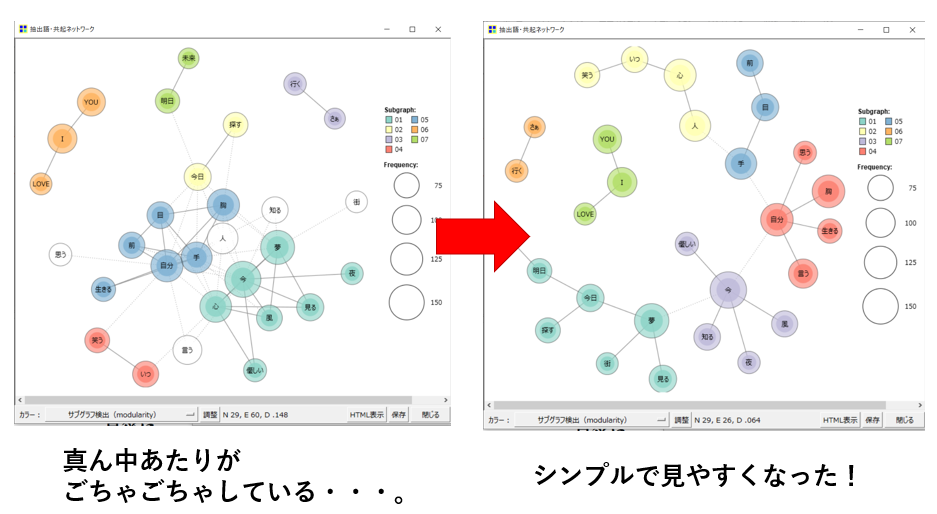
上の図は、最小スパニングツリーのみ描画をチェックしただけで、そのほかの条件は全く同じです。
左の方の図は、律儀に共起性を表す線をたくさん書いてますが、それによって図の本来の目的である見やすさに欠けた図になってしまっています。
図はあくまで、見やすく、分かりやすく、にこだわりましょう!
一つの図にパンパンに情報を詰め込んで見にくくなるくらいなら、いっそシンプルな図を2つ、3つ用意した方が、よほど伝わりやすいです。
そう考えている私はほとんどいつもこの項目をチェックしています。
ちなみに、各語の最大Jaccard係数となる共起性のみを書く機能ではありませんので、その点ご注意ください。
――――――――――――――――――――――――――――――――――――
さて、長くなりましたが、共起ネットワークの設定紹介はこのあたりで終わろうと思います。
様々な設定を組み合わせたり試したりしながら、自分の分析に適した共起ネットワークを作ってみてください!
最後に
これまでに抽出後リスト、KWICコンコーダンス、コロケーション統計、そして今回の共起ネットワークと学んできました。
私が考える、KHCoderでを使ったテキストマイニングの最大の利点は、気軽に様々な分析が行える点です。
そのため、共起ネットワークを作って気になった語が出てきたら、KWICコンコーダンスに戻って、その用例を確かめるなど、気になることがあれば様々な機能を組み合わせて、どんどん調べてみてください。
それが、思わぬ大発見につながるかもしれません。
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
↓この記事を読んだ方の多くは、以下の記事も読んでいます。




