
テキストマイニングだけでなく、ビジネス全般でも使われる”表記揺れ”と言う言葉。
今回は、「そもそも表記揺れとは何?」といったところから、
KH Coderを用いたテキストマイニングにおける表記揺れの対処法までご紹介します。
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
表記揺れとは

表記揺れとは、一つの言葉に対していくつかの呼び方があり、それによって表記にばらつきが生じることを意味します。
例えば、
- 犬、いぬ、イヌ
- おしゃれ、オシャレ、お洒落
- スマホ、スマートフォン
- SHARP、シャープ(社名)
などが表記揺れの例です。
これらは同じ意味で使われているのに、表記が違うため「異なる言葉」として認識されてしまいます。
分析にもよりますが、これらを同じ意味としてまとめて集計したいときは、いちいち足し合わせる必要があります。
そんなことをするのはめちゃくちゃ面倒ですよね。
しかし、KH Coderではそんな表記揺れを統一(表記ゆれを吸収とも言います。)できるようなめちゃくちゃ便利な設定があるので、ご安心ください!
表記揺れ吸収の手順
それでは実際に、データを使って表記漏れを吸収していきましょう。
なるべく画像を多めに、細かく解説していきますので、よかったら一緒にやってみてください。
プラグインをインストールする。
まずは、以下のページより、表記揺れ吸収に必要なのプラグインをインストールしましょう。
(KH Coder 掲示板:http://koichi.nihon.to/cgi-bin/bbs_khn/khcf.cgi?no=1010&mode=allread)
No.2934の樋口先生の投稿にあるURLから表記揺れのプラグインをデスクトップにダウンロードしてください。
ダウンロードが完了すると、以下の手順で表記揺れのプラグインを使えるようにしていきます。
ダウンロードしたファイルを開き、なかに入っている「z1_edit_words3.pm」をKH Coderのフォルダの中にある「plugin_jp」のフォルダの中にコピーしていきます。
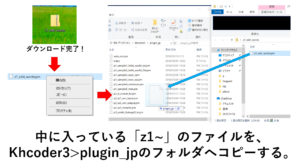
表記揺れ統一ルールの設定
それでは、ここから表記揺れのルールを設定していきましょう。
表記揺れ吸収する語の選定
今回は、以下のような短めの文章で考えていきたいと思います。

Excelの教本に関する短めの口コミが3件あります。
口コミの中には、「Excel」と「エクセル」という二種類の呼び方が混ざっています。
言いたいことはどちらも同じだと思われますが、表記が異なるために別々に集計されてしまいます。
今回は、3つの文章なので手で数えることも簡単ですが、実際のテキストマイニングの現場では、より多くの文章を分析する場合がほとんどです。
そのようなケースでは、表記ゆれをイチイチ数えてられません。
そのため、表記ゆれを吸収するルールを設定することが非常に有効になってきます。
今回は、この「エクセル」を「Excel」に吸収させるようなルールを作っていきます。
表記揺れ吸収ルールの設定
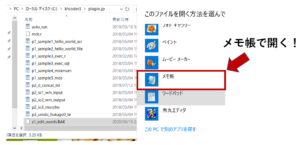
まず、先ほどコピーした「z1_edit_words3.pm」をテキストで開きます。
Macをご使用の場合はテキストエディタで開いてください。
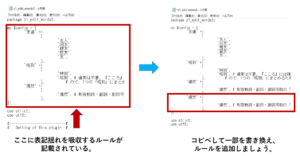
すると、以下のように表記ゆれのルールが記載されています。
ここを書き換えて保存すれば、表記ゆれのルール設定が出来ます。
既にあるものをコピーして、言葉のところを書き換えれば簡単に設定できます。
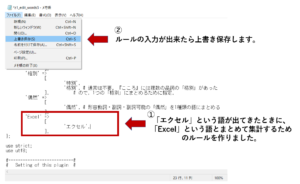
今回は、「エクセル」が「Excel」に吸収される形を作ります。
以下のように入力することで、「エクセル」が「Excel」に吸収されるルールが出来ました。
ルールが入力出来たら、上書き保存しましょう。
これで、準備完了です。
実際に、表記ゆれを吸収していきましょう。
プラグインを使って、表記揺れを吸収する

それでは、KHCoderを開きましょう。
先ほどの口コミ文章のExcelをKHCoderに取り込んで、分析ファイルのチェック、前処理の実行まで行います。
ちなみに、表記ゆれを吸収する前の状態で、抽出語リストを作成すると、 以下のような結果になります。
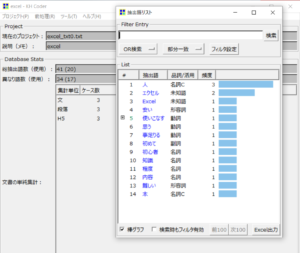
当然ながら、「Excel」と「エクセル」が別でカウントされています。
それでは、実際に表記ゆれを吸収していきます。
「ツール」→「プラグイン」→「表記ゆれの吸収」をクリックしていきます。
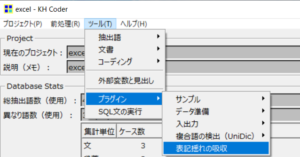
そうすると、先ほど作成したルールに則って、「表記ゆれの吸収」処理が行われます。
表記ゆれの吸収が完了すると、以下のようなポップアップが出てきます。
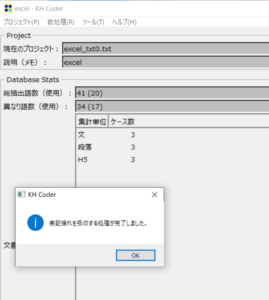
表記ゆれが吸収されたため、異なり語数も減っています。
ここからも表記ゆれの吸収が上手くいっていることが分かります。
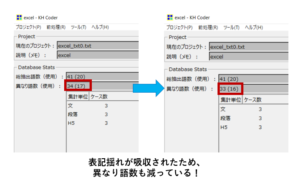
そして実際に、この状態で抽出語リストを作成すると、以下のような結果になります。
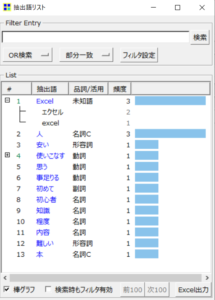
無事「Excel」と「エクセル」統一して集計することが出来ました!
これでいちいち集計結果を足し合わせなくて済みます。
非常に便利なデータクレンジングの手法ですので、覚えておくと便利です。
まとめ

分析する文章が長くなればなるほど、様々な種類の表記ゆれが発生することになると思います。
そして、それら全ての表記揺れを把握し、ルールを設定するのは困難になることもあると思います。
ですので、まずは一度抽出語リストを出してみて、分析に影響しそうな頻出の語に絞ってデータクレンジングをすればよいと思います。
分析結果に大した影響を及ぼさない程度の回数しか出てこない語まで一つ一つルールを設定する必要はありませんから。 そのために、自分はこれからどんな分析をしていくのか、その分析の目的も明確にすることが大切です。
表記ゆれの吸収を利用して、より適切なテキストマイニングを行っていきましょう!
(補足) 表記揺れ以外にも、分析不要な語が含まれている場合はデータクレンジングをする必要があります。
データクレンジングの重要性は以下の記事でも言及しておりますので、是非ご覧ください。
KH Coder講座②分析データの準備 データクレンジングのポイント
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
↓この記事を読んだ方の多くは、以下の記事も読んでいます。




