
今回は、KHCoderを用いた階層的クラスター分析というテキストマイニングの手法をご紹介します。
文書のクラスター分析には、階層的と非階層的の2種類が存在しますが、KHCoderで使うWard法・群平均法・最遠隣法は階層的クラスター分析の一種です。
今後、本記事で出てくる「クラスター分析」は階層的クラスター分析のことを指していると思って、読み進めてください。
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
階層的クラスター分析とは
クラスター分析は、異なる性質のものが混ざった集団の中から、互いに似た性質のものを集めてクラスターにまとめる(グループ化する)分析手法です。
特に、テキストマイニングにおけるクラスター分析は、似たもの同士の語でグループ分けをする分析といえます。
文章は、様々な語が組み合わさって成立しています。
これらの語を関連の強さでグループ化し、それぞれのつながりを明らかにしていくことが出来る点がクラスター分析の大きな特長です。
クラスター分析の手順
まず、「ツール」→「抽出語」→「階層的クラスター分析」とクリックしていきます。
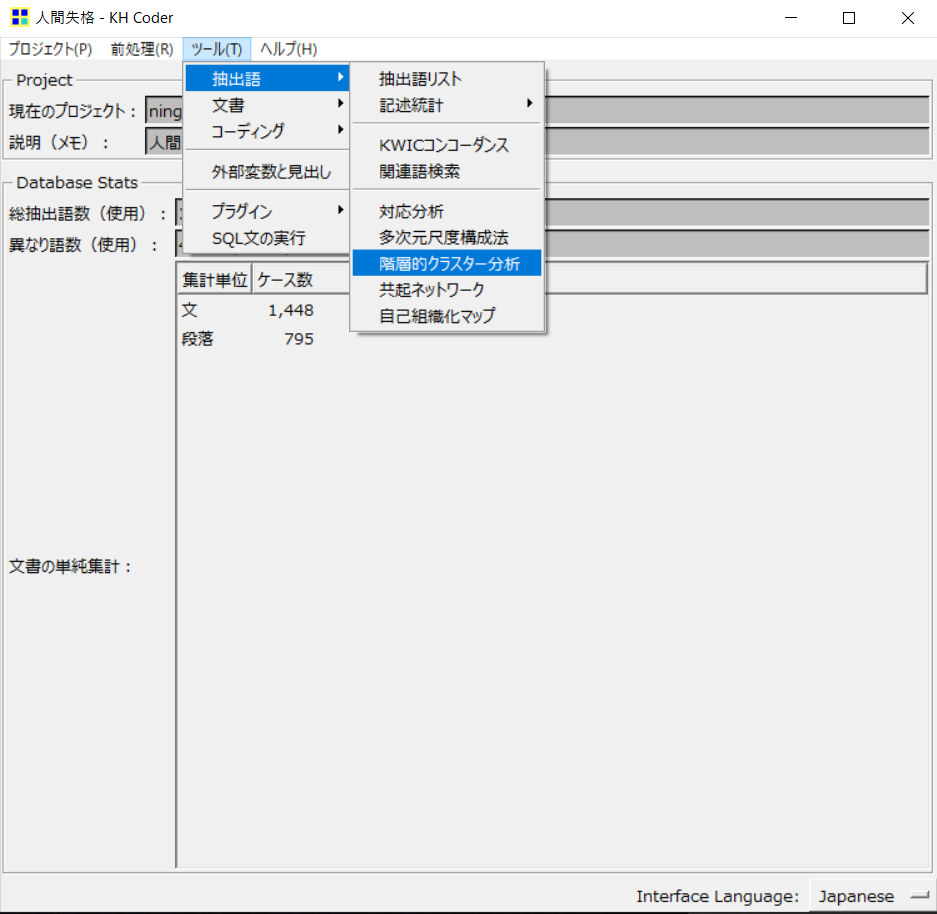
そうすると、クラスター分析の設定画面が出てきます。
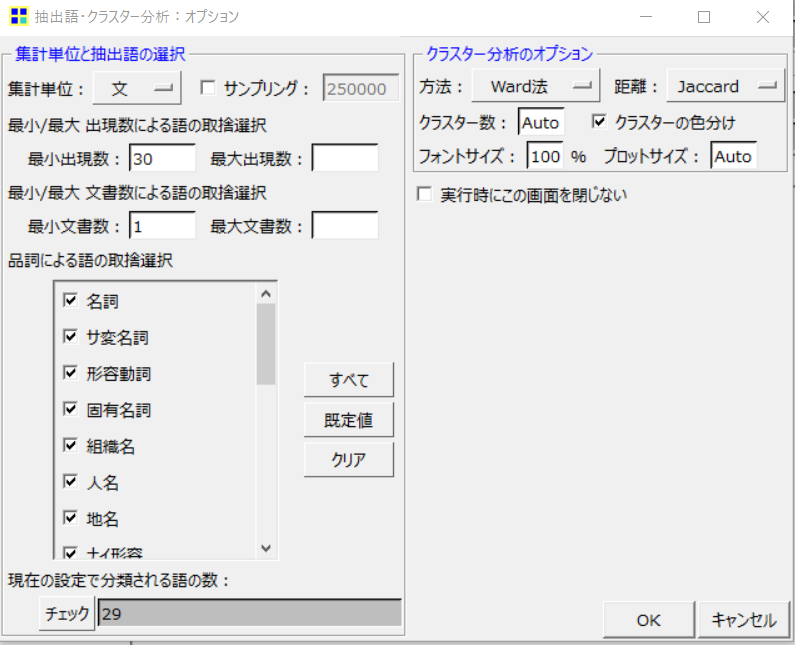
どこかで見たことあるような気がしませんか?
そうです。
左半分は、共起ネットワークを作成した際の設定画面と全く同じです!
実は、「集計単位と抽出語の選択」の箇所はKHCoder内の共通の設定項目なのです。
そのため共起ネットワークなどで選択した設定は、クラスター分析や対応分析など、他の分析に切り替えてもそのまま反映されます。
分析方法を変えるたびに都度設定し直さなくて済むので、非常に便利ですね。
それでは、まずデフォルトで「OK」をクリックしてみます。
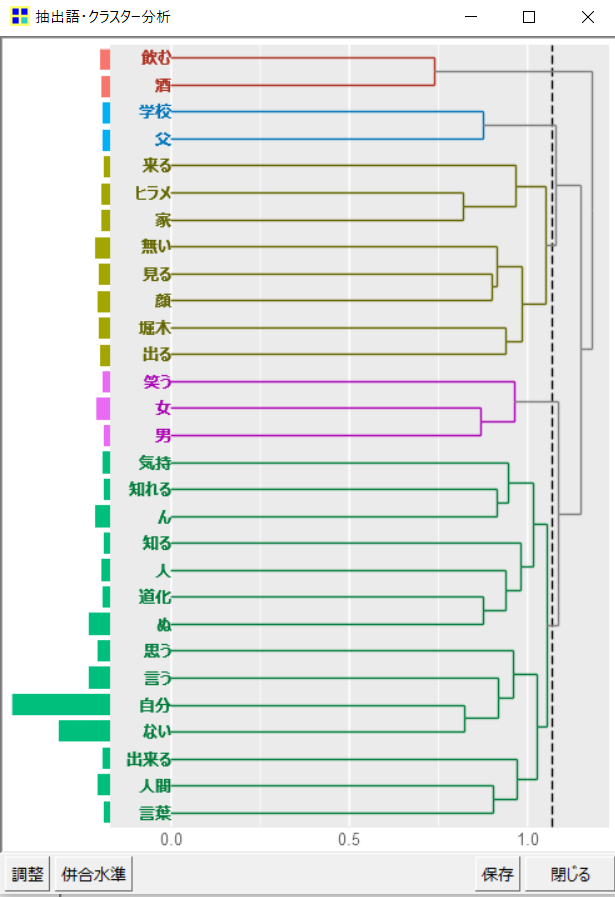
すると、上のようなデンドログラム(樹形図)が表示されました。
表示された分析結果をどのように読み取ればよいのかを説明していきます。
クラスター分析の読み取り方
まず、デンドログラムの右側にある点線をみてみましょう。
実は、この点線より左にある塊が、1つのクラスター(グループ)であることを示しています。
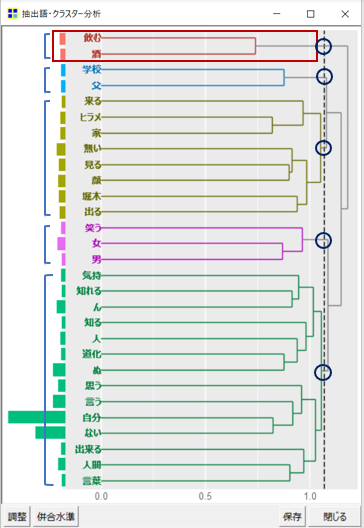
上の図で丸で囲った箇所のように、点線とデンドログラムの線が交わる数を数えると分かりやすいと思います。
今回の場合は、5つのクラスターに分類されたということですね。
同じクラスターに分類された語は関連が強く、線で結びついている語同士も関連が強いことを示しています。
また、語の左側のグラフは語の出現数を表しています。
「自分」という突出した語があることで、そのほかの語の差が分かりにくくなっていますが、これはオマケのようなものなのでかまわないでしょう。
(語数を調べたければ、抽出語リストを使うのがベストなので)
さて、クラスター分析の出力結果をみて思ったことがあります。
それは、「下半分近くが同じクラスターに分類されている」という点です!
ちょっと分類が大雑把過ぎたかもしれません。
そんな場合は、クラスター数を調整することで、より分かりやすい分析結果を出すことが出来ます。
併合水準を使いこなす!
クラスターの数が少なすぎる場合、グループ分けが特徴のクラスター分析の効果は薄くなってしまいます。
とはいえ逆に多すぎると、細分化されすぎて結果が読み取りにくくなってしまいます。
しかし、クラスターの数には「〇個がいい!」といった明確な基準はありません。
じゃあどうやってクラスター数を決めたらええんや!って思うかもしれませんが、さすがはKHCoder。
クラスター数を決める参考として有効な機能がKHCoderにはあります。
それが、併合水準です。
併合水準とは、非類似度(似ていない度合い)のことです。
デンドログラムの左下にある「併合水準」をクリックします。
すると、以下のような図が出てきました。
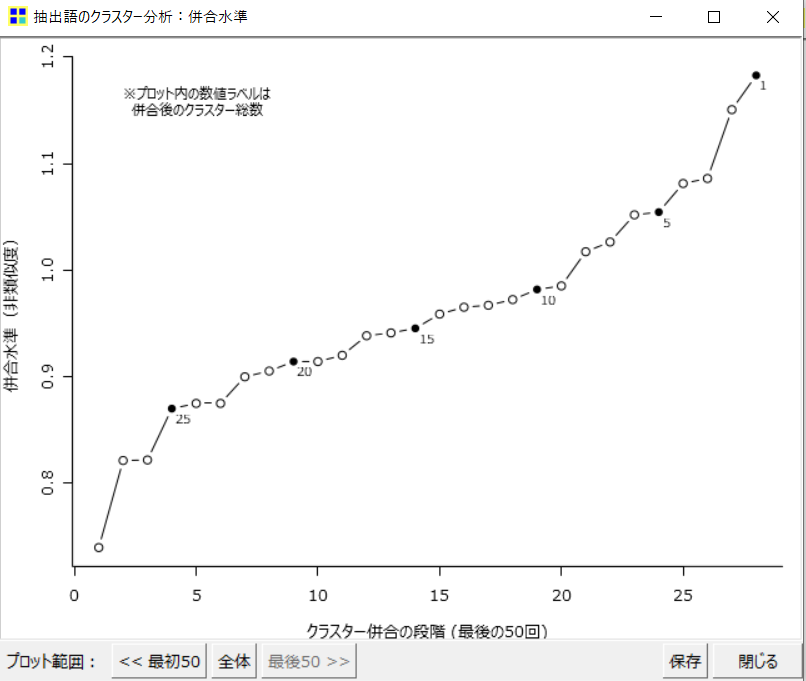
横軸は「クラスター併合の段階」、縦軸は「併合水準(非類似度)」と書いてあります。
縦軸の、非類似度が高いほど似ていないということになります。
右上の1と書いてある黒丸があります。
これはクラスターの数を示しているのですが、クラスターが1ということは抽出された語を全て1つのグループにまとめているということです。
そうすると当然クラスター内の語を見たとき、様々な語が混ざっており似ているレベルが低い、つまり非類似度が高い、ということになるのです。
さて、今回の場合クラスター数は5でした。
併合水準の5のところを見ると、そこそこ非類似度が高いように感じます。
少しでも非類似度を低くするためには、クラスター数を増やすことが有効ですが、どれくらい増やせばいいのでしょう。
クラスター数5のところから少しグラフを下に辿っていきます。
すると、8~9の間で角度が急に変わっている(非類似度が下がっている)ところがあることが分かりました。
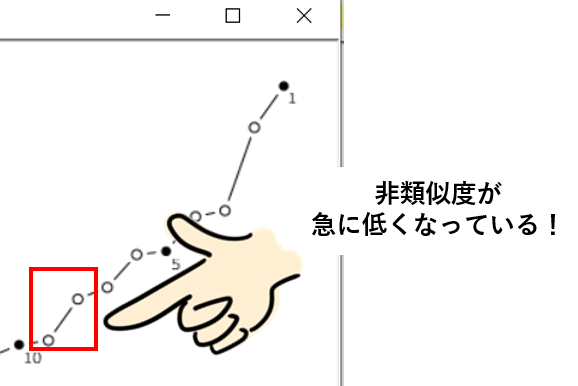
つまり、9つのクラスターにすることで、5つの時よりも非類似度の低い、より有益な分析結果が出てくると考えられるのです。
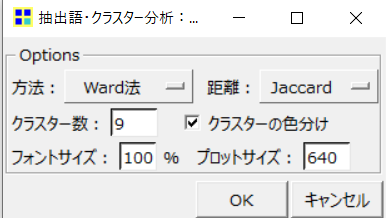
そこで、デンドログラムの左下の「調整」ボタンから以下の画面を開き、クラスター数を5から9に変更して「OK」をクリックします。
すると、以下のようにクラスター9つのデンドログラムに変わりました。
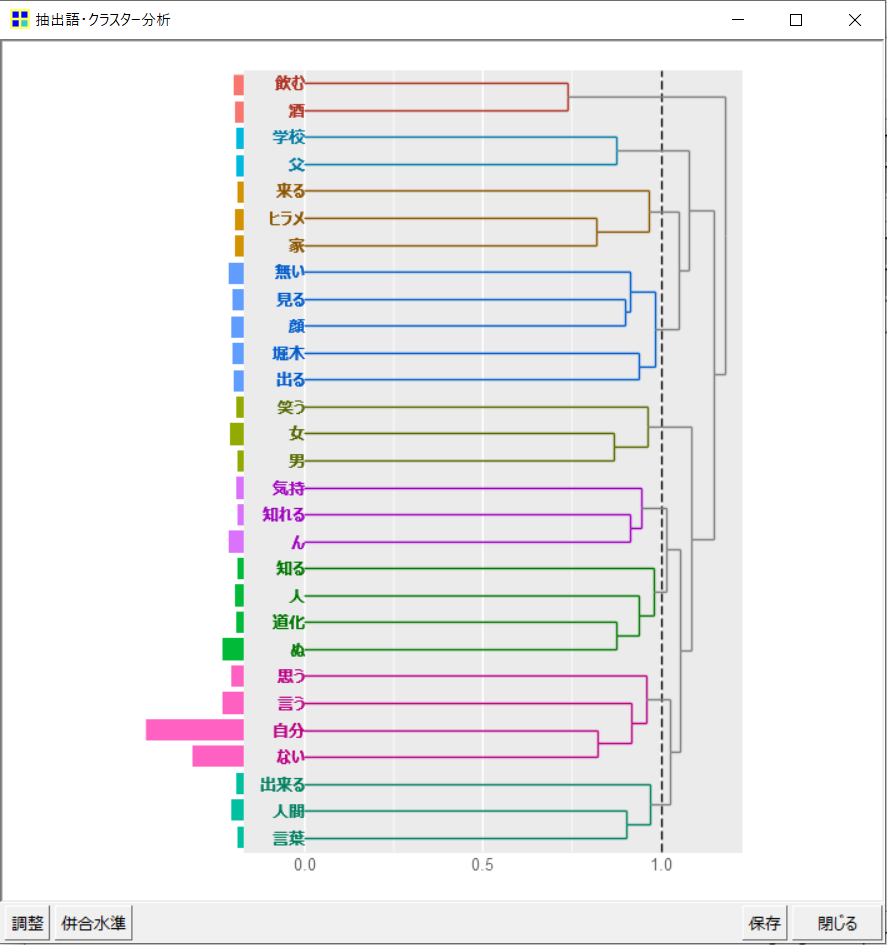
先ほどよりも、より細分化されてそれぞれのグループの特徴をつかみやすくなりました。
①酒
②学校と父の関係性
③ヒラメと家
④堀木関連
⑤男と女が笑っている
⑥気持ちが分からない
⑦人は道化であるということを知る
⑧自分は思わない、言わない、否定が多い?
⑨人間が言葉を使えること?
①~④は、酒や学校、人物など、人やモノに対する特徴で、⑤以降は人間の内面に関する特徴のようにもみえます。
そのため、最初のクラスター数5つの分析では、⑤~⑨がまとまった出てきたとも考えられます。
上記のポイントを踏まえて、KWICコンコーダンスを確認したり、分析を進めていくとよいでしょう。
最後に
クラスター分析を使ったことで、小説の大まかなポイントをつかむことが出来ました。
ただし、分析で出た結果はあくまで機械的に出力した結果です。(クラスター分析に限った話ではないですが・・・)
たとえば、「笑う」という言葉がデンドログラムに出てきています。
このデンドログラム上の「笑う」をクリックすると、KWICコンコーダンスが出てきます。

「笑う」という言葉が出てきて、案外ポジティブな言葉も多いのかと思いきや、
「醜く笑っている」「少しも笑っていない」「顔をゆがめて笑っている」などの使用例を見ると決してそんなこともないのだと分かります。
テキストマイニングの場合、同じ語でも文脈によって意味が変わることもあります。
そのため、分析結果をさらに深堀りするために、KWICコンコーダンスで実際の文を確認することも重要だということも忘れず、分析を行ってください。
さて次の記事では、散布図を使って関係性をマッピングする対応分析(コレスポンデンス分析)を紹介していきます!
▼▼▼【初心者にオススメ】KHCoderオフィシャルガイドブック▼▼▼
▼▼▼【初~中級者にオススメ】KHCoderを開発した先生の著書!▼▼▼
↓この記事を読んだ方の多くは、以下の記事も読んでいます。




