
こんにちは!統計ブロガーのにっしーです!
今回はF検定について説明していきたいと思います!
この記事を読むと分かること
- F検定の概要
- F検定を使うときの注意点
- 他の検定との違い
ビジネスをしていると、2つの店舗の売上の違いや新商品と前の商品の販売数の違いなど、2つのデータの集合の違いを比較する場面があるでしょう。このような2つのデータが与えられたとき、2つのデータがどれだけ違うかをあなたならどう判断するでしょうか。多くの人が一番先に思いつくのが、平均値を比較することでしょう。では、もし平均値がほとんど変わらない値であれば、2つのデータに違いはないと結論づけられるでしょうか。
F検定はこのように、「2つのデータの集合に分散の違いがあるか」を調べるための統計学的手法です。この記事では、F検定の概要や注意点、他の検定との違いや具体例を説明していきます。
F検定とは
F検定とは、2つのデータの集合の分散が等しいかを検定する手法です。分散とはデータの散らばり具合を示す数値で、値が大きいほどデータの値がバラバラに存在することを示します。
F検定は、この分散に注目して、2つのデータが同じ分散を持っているという仮説が成り立つかどうかを検証します。
F検定を行った結果で求めたP値をもとに、分散に差があるかどうかを判断していきます。
F分布とは
F検定では、F分布という確率密度関数を使います。
F分布とは、独立にカイ2乗分布にしたがう確率分布A、Bとその自由度m、nで表される分布です。
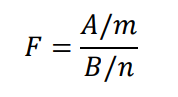
ここで、カイ2乗分布とは、母分散の区間推定や適合度の検定に使われる分布のことをいいます。
また、自由度とは、「与えられたデータのうち、自分で自由に値を決められる値」のことを表します。
例えば、三角形の内角は、180度と決まっているので、2つ角度を決めてしまうと残りの1つの角は自動的に決まってしまいます。
このようなとき、自由度は2だと言えます。
さらに、比較するデータがそれぞれ独立に正規分布にしたがう場合、それぞれのデータをデータA、データBとするとFは以下のように表されます。
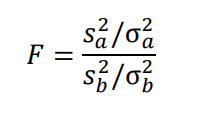
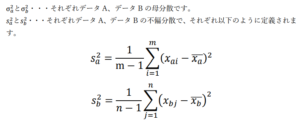
ここで、![]()
![]() と
と![]() はそれぞれデータA、データBの個々のデータの値、
はそれぞれデータA、データBの個々のデータの値、
![]()
![]() と
と![]() はそれぞれデータA、データBの標本平均を表します。また、
はそれぞれデータA、データBの標本平均を表します。また、![]() と
と![]() の分母にあるm-1とn-1は不偏分散の自由度を表しています。
の分母にあるm-1とn-1は不偏分散の自由度を表しています。
データA、データBの自由度がm、nであるのに対し、不偏分散の自由度がm-1、n-1になることに注意しましょう。これは、標本平均が制約条件としてあることにより、1だけ自由度が減ったためです。つまり、先程の三角形の例のように、すべてのデータの足し算の合計の値が決められているので、データの値を順番に決めていくと残りの1つのデータは自動的に決まってしまうのです。
F分布は2つのデータの自由度の値によって、形が変わります。以下の図はF分布のいくつかの例を表したものです。
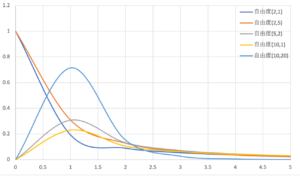
自由度が大きくなればなるほど、統計量Fの値が1になる確率が大きくなることがわかります。
F検定の注意点
F検定を利用すれば、2つのデータの集合の分散に違いがあるかを調べられます。しかし、どの2つのデータ間でもF検定が使えるわけではありません。
F検定を利用するには、2つのデータがそれぞれ正規分布にしたがっていなければなりません。
したがって、F検定をする際にはまず、2つのデータを図示して、正規分布にしたがっているかを確認しましょう。
F検定と他の検定との違い
統計学には他にもt検定やカイ2乗検定などの検定方法が存在します。F検定とそれぞれの検定はどう違うのでしょうか。
t検定は2つのデータの平均値に差があるかどうかを知りたいときの手法です。
また、カイ2乗検定は値が連続していない変数同士に関連があるかどうかを調べるための検定です。
一方、F検定は2つのデータの分散が等しいかどうかを調べるための検定です。
それぞれの検定で調べたいものは異なるため、あなたが調べたいものごとにどの検定を使うかを判断しましょう。
ExcelでF検定を行う方法
Excelの関数であるF.TEST関数を使用してF検定を行います。
これからF.TEST関数を使用して検定する3つの方法を説明します。
例として、ある商品の性別による満足度の分散に差があるかどうかについて、F検定を行います。
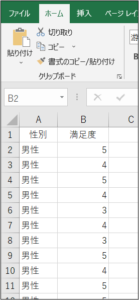
セルに直接、関数を手入力する方法
1つ目の方法は、セルに直接、関数を手入力する方法です。
①セルにカーソルがある状態で、「=f」と入力すると、Fから始まる関数の一覧がプルダウンで表示されます。
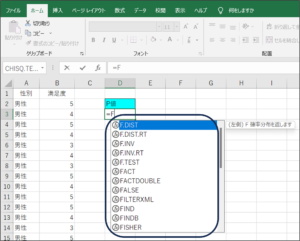
②下矢印で「TEST」までフォーカスを移動させ、Tabキーを押します。
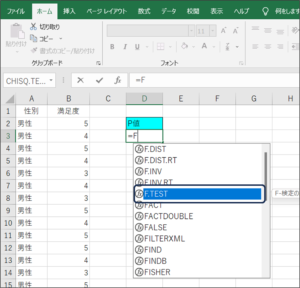
③TEST関数で比較するデータの入力待ち状態となります。
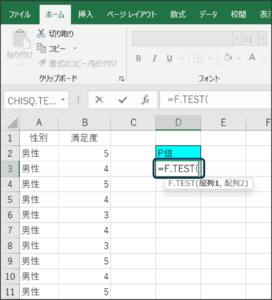
④セルの範囲選択を使用して、男性の満足度のデータを入力します。
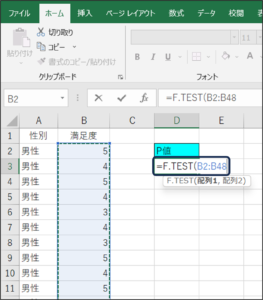
⑤データを区切るため、「,」を入力します。
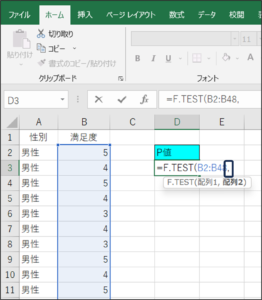
⑥セルの範囲選択を使用して、女性の満足度のデータを入力し、Enterキーを押します。
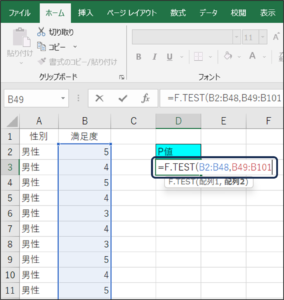
⑦F検定で判断に使用するP値が表示されます。
関数を挿入する方法
2つ目の方法は、関数を挿入する方法です。
①セルが選択されている状態で、fxボタンをクリックします。
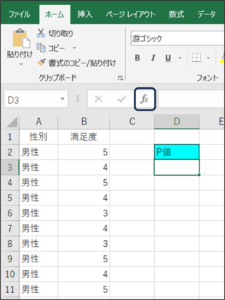
②関数の挿入画面が表示されます。
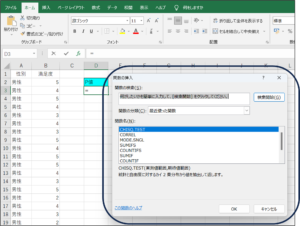
③関数の検索欄に、「F」と入力し、検索開始(G)ボタンをクリックします。
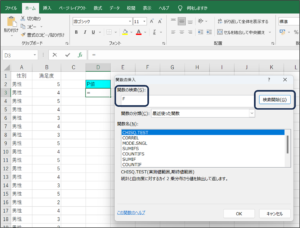
④検索結果の関数名からTEST関数を選択し、OKボタンをクリックします。
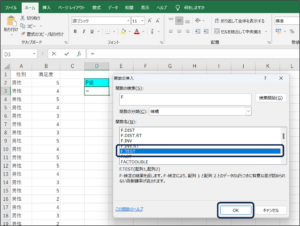
⑤関数の引数画面が表示されます。
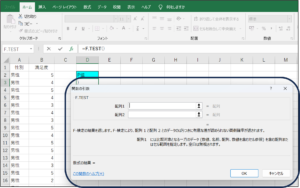
⑥配列1にセルの範囲選択を使用して、男性の満足度のデータを入力します。
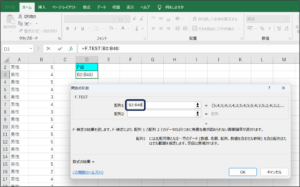
⑦配列2に女性の満足度のデータを入力するため、範囲選択ボタンをクリックします。
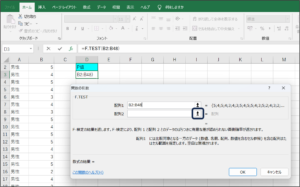
⑧セルの範囲選択を使用して、女性の満足度のデータを入力後、範囲選択ボタンをクリックします。

⑨OKボタンをクリックします。
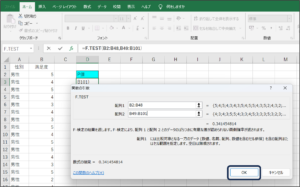
⑩F検定で判断に使用するP値が表示されます。
数式タブから関数を入力する方法
3つ目の方法は、数式タブから関数を入力する方法です。
①セルが選択されている状態で、数式タブのその他の関数の中にある統計のTEST関数を選択します。
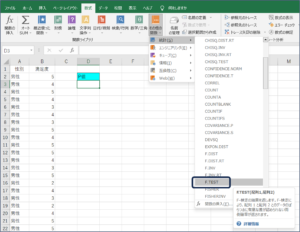
②関数の引数画面が表示されます。
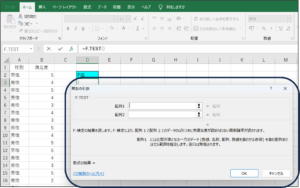
③配列1にセルの範囲選択を使用して、男性の満足度のデータを入力します。
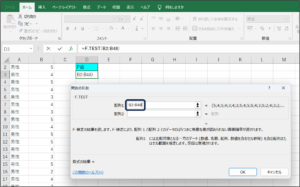
④配列2に女性の満足度のデータを入力するため、範囲選択ボタンをクリックします。
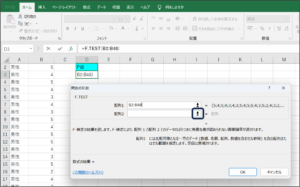
⑤セルの範囲選択を使用して、女性の満足度のデータを入力後、範囲選択ボタンをクリックします。
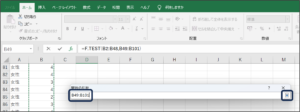
⑥OKボタンをクリックします。
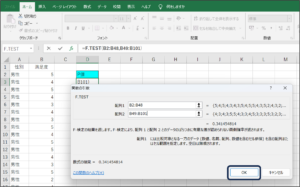
⑦F検定で判断に使用するP値が表示されます。

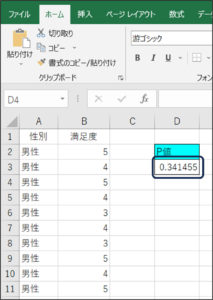
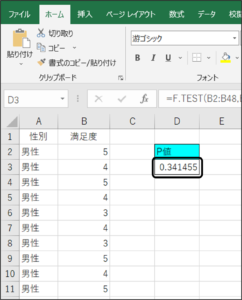
以上の方法で、F.TEST関数によるF検定により、P値を求めることができます。
P値は「0.341455」です。
P値が0.05以下であれば、分散に差がないといわれています。
今回の結果は、0.05以上であるため、「ある商品の性別による満足度の分散に差がある」ということになります。
Excelの分析ツールを使用して、F検定を行う方法
次に、Excelの分析ツールを使用して、F検定を行う方法を説明します。
Excelの分析ツールを使用して、F検定を行います。
分析ツールを使用する前に、Excelの分析ツールが使用できるように設定します。
①Excelを起動し、オプションをクリックします。

②アドインを選択して、管理(A):に「Excel アドイン」を設定し、設定(G) ...ボタンをクリックします。
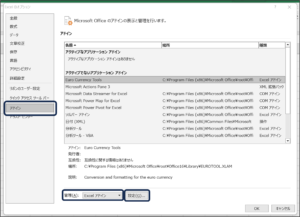
③アドイン画面が表示されますので、分析ツールにチェックをつけ、OKボタンをクリックします。
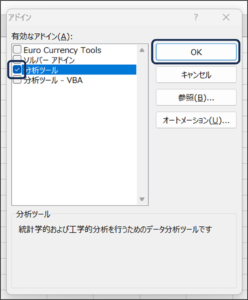
④データタブをクリックし、データ分析が追加されていることを確認します。
データ分析が追加されていれば、データ分析ツールの準備は完了です。

Excelの分析ツールを使用したF検定の方法を説明します。
例として、ある商品の性別による満足度の分散に差があるかどうかについて、F検定を行います。
①データタブからデータ分析をクリックします。
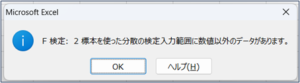
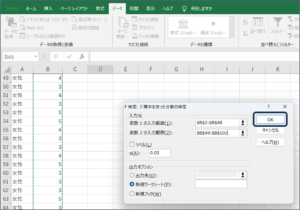
②データ分析画面が表示されますので、「F検定: 2標本を使った分散の検定」を選択し、OKボタンをクリックします。
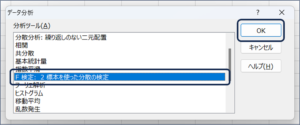
③F検定: 2標本を使った分散の検定画面が表示されます。
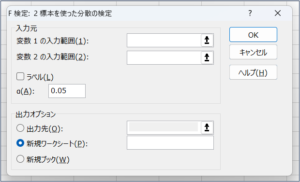
| 項目名 | 説明 |
| 変数1の入力範囲(1) | 比較するデータを範囲選択します。 |
| 変数2の入力範囲(2) | 比較するデータを範囲選択します。 |
| ラベル(L) | データの範囲を選択した際、先頭行の項目名も範囲選択した場合に、チェックを入れます。 チェックを入れ忘れた場合は、以下のようなエラーメッセージが表示されます。 |
| α(A) | 有意水準を指定します。初期値は、「0.05」です。 |
| 出力先(O) | 同じシート内に検定結果を出力する場合に、チェックを入れます。 検定結果を出力する先頭行のセルを指定します。 |
| 新規ワークシート(P) | 検定結果を新しいワークシートに出力する場合に、チェックを入れます。 |
| 新規ブック(W) | 検定結果を新しいブックに出力する場合に、チェックを入れます。 |
④変数1の入力範囲にセルの範囲選択を使用して、男性の満足度のデータを入力します。
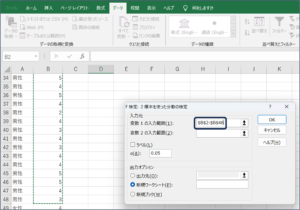
⑤変数2の入力範囲に女性の満足度のデータを入力するため、範囲選択ボタンをクリックします。
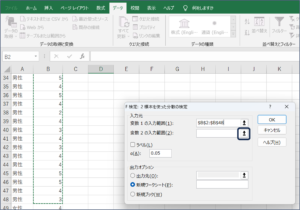
⑥セルの範囲選択を使用して、女性の満足度のデータを入力後、範囲選択ボタンをクリックします。
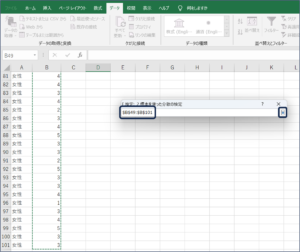
⑦条件を設定して、OKボタンをクリックします。
⑧F検定結果が表示されます。

P値は「0.170727」です。
今回のP値は片側検定の値で、両側検定の値にするために、倍にします。
倍にしたP値は「0.341454」となります。
P値が0.05以下であれば、分散に差がないといわれています。
今回の結果は、0.05以上であるため、「ある商品の性別による満足度の分散に差がある」ということになります。
以上で、Excelの分析ツールを使用した説明は終わりです。
F検定の具体例:日本における過去10年間の男女の平均賃金の分散について
それでは、実際のデータを用いてF検定を行ってみましょう。
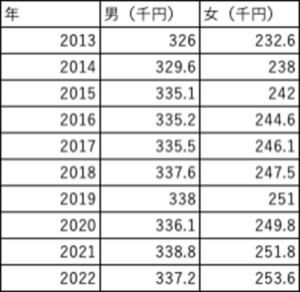
以下は日本での過去10年間の男女の平均賃金を表した表です。
ここでは簡単のため、以下のデータは正規分布にしたがうとします。
https://www.jil.go.jp/kokunai/statistics/timeseries/html/g0406.html
ここで、帰無仮説と対立仮説を以下のように設定します。
- 帰無仮説:男女の賃金の母分散は等しい(
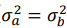
 )
) - 対立仮説:男女の賃金の母分散は異なる(
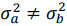
 )
)
帰無仮説とは、検定によって棄却したい仮説のことです。一方、対立仮説は検定によって示したい仮説のことを表します。つまり、ここでは、男女の賃金の分散には差があること示すことがF検定の目的です。
まず、帰無仮説が正しいと仮定しているので、![]()
![]() だから、
だから、
統計量Fは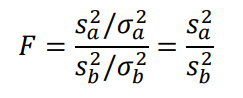 となり、不偏分散の比で表されます。
となり、不偏分散の比で表されます。
まず、男女でそれぞれ不偏分散を計算します。すると、男女の不偏分散はそれぞれ、16.29、43.75となります。
よって、統計量Fは、![]()
![]() になります。
になります。
次に、この統計量Fと有意水準5%でのF分布表とを比較します。
F検定では、一般的に有意水準5%で検定します。
有意水準とは、帰無仮説を棄却するか棄却しないかの基準となる値で、有意水準5%とは、「帰無仮説のもとでその事象が起きる確率が5%である」ことを表しています。
F分布は自由度でその形が変わるので、それぞれの場合でどの自由度を使っているかを考えなければなりません。今回は、男女ともに10年間のデータを扱っているため、自由度は1つずつ減って、(9,9)です。自由度が1つ減るのはここでは不偏分散を扱っているからです。
以下の有意水準5%のF分布表から自由度が(9,9)のときの値を読み取ってみましょう。

自由度が(9,9)のF分布の有意水準5%の値は、3.179です。
これは、データから求めた統計量F=2.685より大きい値です。
この場合、帰無仮説は棄却されず、「男女の賃金の分散には違いがあるということはできない」という結論になりました。
まとめ
F検定は、2つのデータの分散の等しさを検定する統計的手法です。この手法では、2つのデータの集合を平均値の違いだけでなく、分散の違いからも調べることができます。
しかし、F分布には元のデータが正規分布であるといった前提条件があるので注意が必要です。
この記事を通じて、F検定の基本的な理解とその適用方法について把握していただければ幸いです。




