

平成29年総務省の情報通信白書で「ビッグデータ利活用元年」という言葉が出てきました。
それほどに現代はデータの利活用に重きを置かれている時代であり、今や私たちの身の回りはたくさんのデータであふれています。
そして、今後もデータが増え続けていくのは間違いないでしょう。
そんな世の中にあふれているデータですが、それらのデータは必ずしも正しいものとは限りません。
なかには、自らの主張を通したいがために、あえてウソのデータ・分析結果を使う人もいます。
(有名な言葉で「数字はウソをつかないが、嘘つきは数字を使う」という言葉があります。)
また、悪気はなくても、誤ったデータ、分析結果となってしまっているケースもあります。
正しいデータや正しくないデータが入り混じった世の中を生き抜くには、そのデータが信頼に足るものなのか見抜くためのデータリテラシーを身につけることが必要になってきます。
今回は、世の中にはびこるデータのウソを見破るためのコツをいくつかご紹介します。
この記事を読むと、以下のことが分かるようになります!
この記事を読むと分かること
- データリテラシーとは
- データのウソの見抜き方
最後まで楽しんで読んでください!
データリテラシーとは
データリテラシーとは、データを読むスキル、活用するスキル、分析するスキルなど、データに関する様々スキルの総称です。
現代では、情報機器の発達により、あらゆる場所にデータが存在します。
例えば、私たちが使っているPC、スマホや、電車に乗るときのSUICAなどの履歴、スーパーやコンビニで購入したデータ、企業内の顧客データ、販売データなど、データとのかかわりを全く持っていない人はいません。
私たちが好む好まざるにかかわらず、データとともに生きていくことは必然です。
しかし、データをうまく活用するスキルがあれば、仕事でもプライベートでも役に立つことが多々あります。
また、データを使ったウソもデータリテラシーさえ身につけておけば、騙されずに見抜けるようにもなります。
現代の情報社会を生き抜くためには、データリテラシーを身につけることが必須だといっても過言ではありません。
データに潜むウソを見抜くコツ!
さて、ここからはデータに潜むウソを見抜くコツをご紹介します。
冒頭でもお伝えした通り、データを使う人の中には、自分の主張を通したいがためにあえて誤った解釈をしてしまうようなデータを表示することがあります。
そんなデータに惑わされないようになるためには、いくつかのコツを身につけておけば、騙されるリスクは格段に下がります。
以下では、そのコツを分かりやすくまとめたので、是非この機会に身につけてください!
データ分析の具体的な方法は明記されているか
まずチェックすべき項目として、その分析対象がどのような条件で収集され、どのような方法で導き出されているのかが明記されているかどうかを確認しましょう。
分析方法などが明記されていない場合、自分たちの都合のいいようにデータを使っている可能性も考えられます。
例えば、「令和元年(2019年)家計の金融行動に関する世論調査[単身世帯](金融広報中央委員会)」によると、20代の平均貯蓄額は106万円となっていました。
しかし、20代の平均貯蓄額の中央値をみると、5万円でした。
つまり、外れ値である一部の富裕層によって平均が引き上げられたことで、このようなデータが出てしまうのです。
この場合の平均貯蓄額106万円はウソのデータではありませんが、実態を正しく示しているとも言えません。
20代は貯蓄が多いという風にいいたければ平均値を使うし、少ないと見せたければ中央値が使われるのです。
いいデータは、どちらも記載されていることです。
正しくサンプリングされているか
正しくサンプリングされているかはデータの信頼性を判断するうえで、非常に重要な要素です。
サンプリングとは、調査を行う際に母集団(全体)から調査対象となる標本を一部抜き出すことを意味します。
例えば、「渋谷で100人に聞き取り調査」と書いてあったとしても、男性100人に聞くのと、女性100人に聞くのとでは、結果が変わってくる可能性があります。
そのため、「渋谷の20代男女100人に聞き取り調査(男性50名女性50名)」など細かくサンプルの内容を書かれており、その内容も極端な偏りがないものの方が、調査の信頼性が高いといえます。
グラフ内の数字はおかしくないか
数字だけでなく、グラフを使ってデータの解釈をねじ曲げる事例もあります。
例えば、以下の画像を見てください。
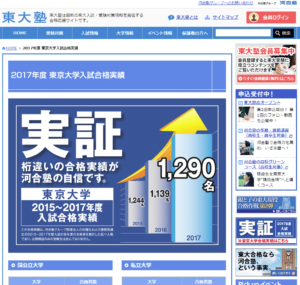
以前ネットで話題になった画像ですが、某予備校の合格実績です。
グラフや矢印を見ると、合格実績は年々増えているように見えます。
しかし、数字の部分をよく見ると・・・
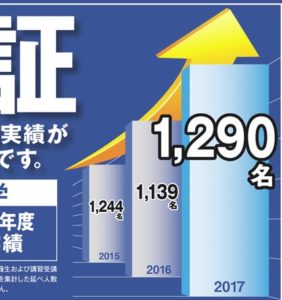
なんと、2015年→2016年で減っているにもかかわらず、遠近法を駆使してあたかも合格者数が年々増えているように見せかけていたのです。
実際にこのようにデータを自分たちの都合の良いように解釈させようとすることはよくあることです。
もしかしたら私たちも気づかない間に不正なデータ・情報をつかまされているかもしれないのです。
グラフをみるときは、軸や値が適切になっているかは確認は必須といえます。
追試可能性があるか
分析結果は、他の人が実施したときにも再現できるかどうか(追試可能性)が非常に重要です。
例えば、小保方さんのSTAP細胞の騒動が分かりやすいです。
小保方さんは、STAP細胞が出来たと発表しました。
ただ、発表後に再現できなかったためにウソだと非難されてしまいました。
本当にSTAP細胞が作れたのか、作れなかったのかは、当事者以外誰にも分かりません。
しかし、再び作れていればその信頼はゆるぎないものになっていたでしょうし、嘘かどうか論争も起こらなかったはずです。
このように、追試可能性があるかどうかというのは、分析結果の信憑性に大きく変わってくる重要な要素といえます。
追試可能性が低いものについては、正しくない情報である可能性も考えなくてはなりません。
第三の変数による影響
たとえば、交通事故は女性よりも男性のほうが件数が多いといわれています。
しかし、だからといって「男性のほうが女性よりも運転が下手だ!」とは言えません。
なぜなら、そもそも一般的に女性よりも男性のほうが運転する機会が多いからです。
つまり、交通事故件数と性別に関連があるのではなく、性別と運転する距離・機会の多さなどに関連があり、そして運転する距離や機会の多さと交通事故件数に関連があると考えたほうが自然です。
このように一見直接関連するように見えて、間に第三の変数が潜んでいることがあります。
今回の例では、運転する距離が第三の変数にあたります。
データの関連性を見るとき、このような第三の変数が隠れていないかを確認することも重要です。
このような第三の変数が含まれていることにより疑似相関と呼ばれる、因果関係がないのに相関関係がある、といった事例も多数あります。
詳しくは以下の記事でご紹介しているので、気になった方は是非読んでみてください。
疑似相関(見せかけの相関)の具体例11選!~警察官が増えると検挙数が増える!?~
最後に
データが溢れる世の中になったからこそ、そこに正しくないデータが出てくるのもごく自然なことです。
だからこそ、自分を守るためには、データリテラシーが必要になってきます。
データがあふれる現代をサバイブするうえでは、データリテラシーはもはや欠かせないものになっています。
是非この機会にしっかり身につけましょう!
↓この記事を読んだ方の多くは、以下の記事も読んでいます。




